Recent neural human representations can produce high-quality multi-view rendering but require using dense multi-view inputs and costly training. They are hence largely limited to static models as training each frame is infeasible. We present HumanNeRF - a neural representation with efficient generalization ability - for high-fidelity free-view synthesis of dynamic humans. Analogous to how IBRNet assists NeRF by avoiding per-scene training, HumanNeRF employs an aggregated pixel-alignment feature across multi-view inputs along with a pose embedded non-rigid deformation field for tackling dynamic motions. The raw HumanNeRF can already produce reasonable rendering on sparse video inputs of unseen subjects and camera settings. To further improve the rendering quality, we augment our solution with in-hour scene-specific fine-tuning, and an appearance blending module for combining the benefits of both neural volumetric rendering and neural texture blending. Extensive experiments on various multi-view dynamic human datasets demonstrate effectiveness of our approach in synthesizing photo-realistic free-view humans under challenging motions and with very sparse camera view inputs.
Overview
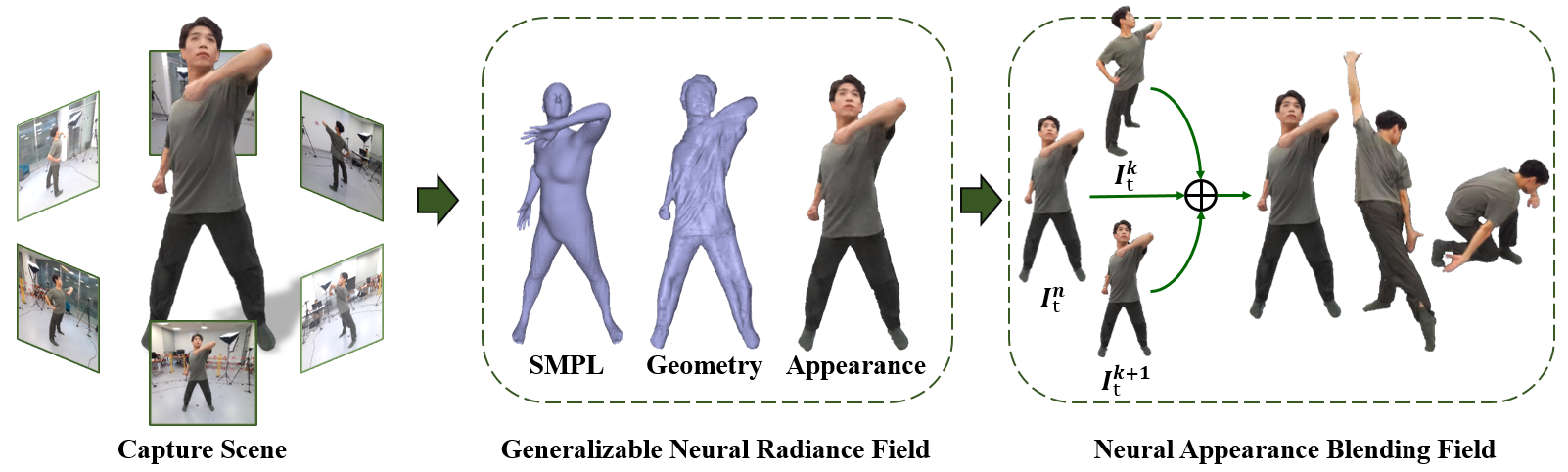
The overview of our HumanNeRF method. Assuming the video input from six RGB cameras surrounding the performer, our approach consists of a generalizable neural radiance field, an optional fast per-scene fine-tuning scheme and a novel neural appearance blending field.
Result

Our proposed HumanNeRF utilizes on-the-fly efficient general dynamic radiance field generation and neural blending, enabling high-quality free-viewpoint video synthesis for dynamic humans. Our approach only takes sparse images as input and uses a pre-trained network on large human datasets. Then we can effectively synthesize a photo-realistic image from a novel viewpoint. While these results contain artifacts, we fine-tune 300 frames for a specific performer using only an hour and generate improved results.
Results

Paper
